

Want more info on Encipher®?
We'd love to work together! Email us and we'll get right back to you.
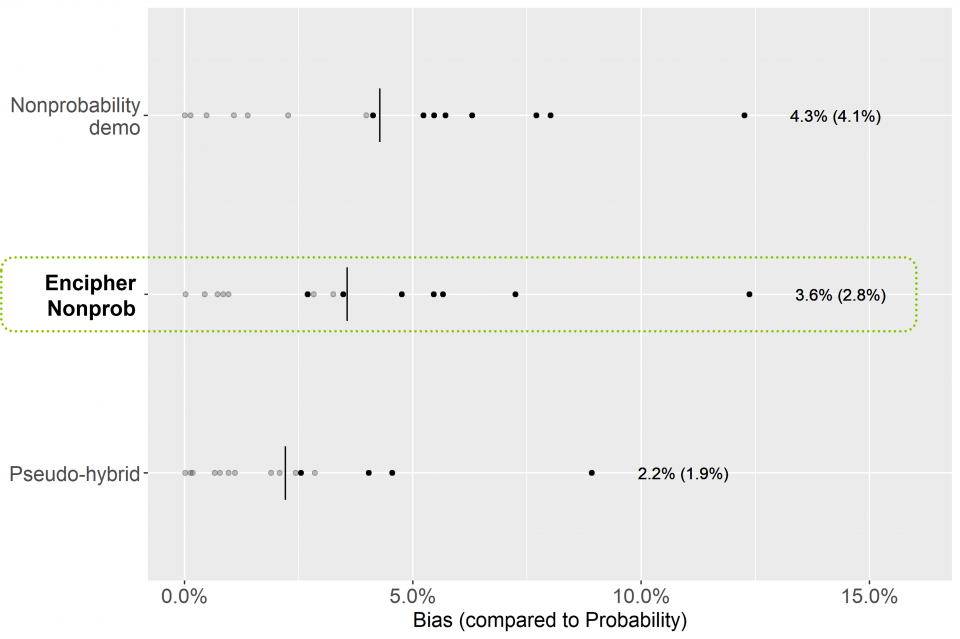
Improving Weighting for Nonprobability-only Samples
By leveraging the SSRS Opinion Panel and advanced predictive modeling techniques, Encipher Nonprob allows the SSRS Calibration Item Bank and a version of the SSRS Stepwise Calibration algorithm to be applied to nonprobability-only samples.
As with Encipher® Hybrid, Encipher® Nonprob requires that a small selection of calibrators from the Calibration Item Bank—customized to the topic of the study—be included on the study questionnaire.

Learn more about how Encipher® Nonprob reduces the median selection bias by over 30% relative to standard demographic-only weighting of nonprobability-only samples.
Read It
A Validated Methodology for Blending Probability and Nonprobability Samples
Encipher® Hybrid is a unique and sophisticated method that leverages study-specific outcomes, advanced modeling techniques, and customized non-demographic measures to produce weighting margins that are optimized for reducing selection bias in key study outcomes.
Learn MoreWe'd love to work together! Email us and we'll get right back to you.

The SSRS Methods, Analytics, and Data Science (MADS) team created Encipher®. They conceptualize and manage survey data collection from design to dissemination, and have extensive expertise in methodological experimentation, sampling, weighting, data collection planning, monitoring, adaptive and tailored design, data editing and imputation, documentation, reporting, and quantitative analysis. Get to know the MADS team.
Meet MADSOur highly experienced SSRS Methods, Analytics, and Data Science (MADS) team conceptualizes and manages survey data collection from design to dissemination. Let's start a conversation about how we can help with your next project!
Let's Talk




